Our team is building a Platform as a Service (PaaS) for government so developers can quickly and easily host websites. We’re using the open source Cloud Foundry (CF) technology to ensure reliable hosting, and Amazon Web Services (AWS) for our underlying infrastructure.
Recently we found an odd and challenging issue. One of our smoke tests (that we run periodically against our environments to detect any problems) began failing but only in our production environment and only when CF account usernames fell within a specific length range.
After chasing the problem down through the CF stack, we finally found the culprit: AWS networking (we are unsure which element of the network was involved) was dropping Ethernet packets in a very specific set of circumstances. This was whenever we connected AWS Virtual Machine Instances routed with network address translation (NAT) gateways to Amazon Elastic Load Balancer (ELB).
In this post, we'll share how we stopped this happening and what we learned along the way.
Smoke tests failing in our CF production environment
We constantly run the official Cloud Foundry smoke tests in all our environments. One morning, we found that our automatic tests were failing while deploying a test web application to our CF production environment. We were getting the following error every 10 seconds until the deployment failed:
Could not fetch instance count: Server error, status code: 503, error code: 200002, message: Stats unavailable: Stats server temporarily unavailable.
This didn't happen in our other environments, or even when we ran the tests manually in the very same environment.
We spent hours trying to work out what was going on until we found out the CF username length was involved. The error only happened with usernames between 34 to 38 characters long. The automatic tests had used temporary usernames like continuous-smoketest-user-LVuCeLYtNS (36 characters), while our manual test had used short usernames like admin or mytestuser.
Still confusing us though was that even when testing with a username in the affected length range, sometimes the tests would run fine for a few minutes before the error cropped up again.
Finding the root cause of failure
We quickly shortened the usernames so that the smoke tests ran okay, but there were still plenty of open questions, eg why were we only getting error messages in the production environment and why were these messages intermittent? We decided to dissect the Cloud Foundry stack to find out what was failing.
CF's Cloud Controller directs the deployment of applications and provides REST Application Programming Interface (API) endpoints for CF clients, like cf-cli or web interfaces, to call the PaaS system. By tracing these client calls, we identified the origin of the error, which said:
But the Cloud Controller code was swallowing the exception.
We traced the code further down the Cloud Controller stack. The next service being called was Diego (the CF backend that Cloud Controller uses to stage and run applications). We focussed on the Cloud Controller code for Diego and found out that calls being made to the TPS Listener, which provides information about the application’s running processes, were timing out after 10 seconds.
Looking in the TPS Listener problems
We then checked our log aggregator to find out more on the errors with TPS Listener. There was some problem with TPS Listener calling Doppler, which is a CF component that gathers logs and metrics on an application’s performance. This was the error:
"error" : "Error dialing traffic controller server: Get https://doppler.cloud.service.gov.uk:443/apps/3d8b40ff-e17c-4d71-bac4-83675209a810/containermetrics: EOF.\nPlease ask your Cloud Foundry Operator to check the platform configuration (traffic controller endpoint is wss://doppler.cloud.service.gov.uk:443).",
"log-guid" : "3d8b40ff-e17c-4d71-bac4-83675209a810"
But we didn't find any related errors in the Doppler service.
By examining the code, we found out that TPS Listener was using the NOAA client library to connect to Doppler. The call to connect had no explicit timeout defined. As a result, when TPS Listener was unable to get a response from Doppler, the connection didn't time out quickly enough, and Cloud Controller's original call to TPS Listener timed out first (after 10 seconds).
Interestingly, we were only able to reproduce the issue when we crafted a manual request to the Doppler endpoint from the command line using curl that mimics all the headers of the original call, including the HTTP headers for Host, Encoding and User-Agent.
Using tcpdump to troubleshoot the network
The lack of log messages from Doppler and the timeout suggested some kind of network issue.
We decided to use tcpdump (a command-line packet analyzer) on the server where TPS Listener was running to capture the communication between TPS Listener and the remote AWS ELB, which is used to load balance Doppler. Then, visualising the Transmission Control Protocol (TCP) stream using wireshark, we could tell that TCP packets of a particular size were being dropped:
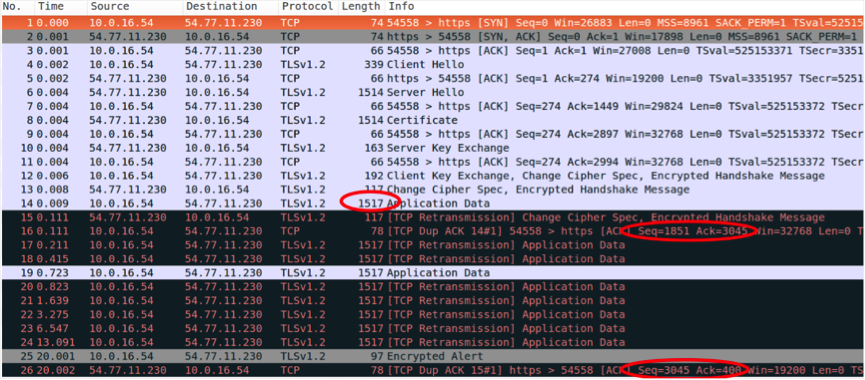
After the Secure Sockets Layer handshake (packets 1-13), which allow the client and server to authenticate, the payload with the encrypted HTTP request is sent as a data packet.
This request includes a token with the username info, the hostname, and HTTP headers, which makes a total packet size of 1517 bytes. This 1517 bytes packet (packet 14) is retransmitted (packets 17-24) and never acknowledged by the ELB. Meanwhile smaller packets passed through correctly. So somehow packets of a specific size (1517 bytes) were being dropped by AWS.
Packet drop due to MTU
Everything pointed to a packet drop between the virtual machines (VM) and the ELB endpoint, probably caused by issues with Path Maximum Transmission Unit Discovery (PMTUD). Using PMTUD all the network devices that are part of a connection should be able to negotiate the optimal maximum transmission unit (MTU) to avoid IP fragmentation. But if this negotiation is not working and the sender transmits a packet that is too large for some other device in the path, the packet will be dropped and a black hole connection will occur.
We performed a set of tests and these confirmed setting a MTU of 1512 in the original VM prevented the issue from happening. Meanwhile, transferring a packet of 1518 bytes or more stopped the error happening for several minutes; our guess is that the underlying network was able to correctly adapt the MTU in the path when bigger packets were transmitted. We also created an automated test to check for this issue.
Mystery solved
These tests gave us a full explanation of what was going on.
CF uses OAuth2 to authenticate services and generates signed tokens that include meta information like usernames. The tokens are included with every HTTP request across the CF stack. So username length affects packet size, and usernames of a certain length could trigger communication problems between TPS Listener and Doppler.
The packet loss problem only showed up in our production environment because the HTTP request includes the hostname of the Doppler endpoint. Clearly, the length of the domain name also affected packet size and it was only our production domain that happened to have the exact length that triggered the problem.
In general, any factor that changed the HTTP request size would have an impact. A different SSL client like openssl created packets bigger than 1518 during the SSL handshake, preventing the issue from happening for a while. Also a different SSL server certificate in the ELB could force a packet bigger than 1518 during the SSL handshake, and again preventing the issue from happening.
Ticket with AWS and fixing the issue
We opened a ticket with AWS support on 18 May describing the issue. AWS confirmed the issue 2 days later and prepared a fix that was successfully deployed on 12 July.
Until it was completely fixed, as a workaround we reduced the MTU in the VMs by adding a hook to the DHCP daemon. This feature has been later merged upstream in a CF networking release.
Wrapping up
Cloud Foundry is a great platform, but it has a complex architecture with multiple services and integration points that can sometimes be difficult to troubleshoot. You need good tooling and a good understanding of the platform to chase errors, especially if services hide the root cause of an error, as Cloud Controller did.
A distributed architecture like Cloud Foundry requires its component services to be built for resilience, with sensible use of timeouts and circuit breakers. The Cloud Foundry developers understand this and quickly added the right timeouts to TPS Listener to avoid unnecessary delays in the calls from the Cloud Controller.
It’s also important to always review your assumptions. Sometimes the problem is in the infrastructure. It seemed more likely that our own stack, rather than a massive public cloud like AWS, was the source of dropped packets, but by following the code, we were able to trace the root cause of the problem and get it patched for AWS users worldwide.
You can follow Hector on Twitter, sign up now for email updates from this blog or subscribe to the feed.
If this sounds like a good place to work, take a look at Working for GDS - we're usually in search of talented people to come and join the team.

5 comments
Comment by Rod Taylor posted on
Alternatively, as any domestic boiler engineer will tell you, swap out components until it works. It is often more efficient than following and understanding the full journey through multiple components and systems. So, next time, consider just switching it to Azure, to see if the platform was the issue.
Comment by Hector Rivas posted on
Thank you, it's a brave proposal.
Cloud Foundry is deployed using Bosh, which offers some grade of abstraction on the IaaS. We tried deploying CF on Azure in our early alpha of the project (see https://github.com/alphagov/cf-terraform/pull/4) but encountered a number of challenges.
And actually troubleshooting is one of the best exercises to gain experience via reverse engineering. We gained more understanding of the CF stack by following the code.
Comment by Rod Taylor posted on
Oh, you're locked into Amazon? Jeff Bezos will be delighted!
Comment by Hector Rivas posted on
Sorry but we have to disappoint Jeff Bezos this time.
We are not locked in AWS. It is true that currently we're using AWS for our deployment, but our technology stack (Terraform, Bosh and Cloud Foundry) do provide the abstraction to move to another IaaS if we want. Importantly the applications are not tied to the underlying infrastructure and could be migrated without changes.
It is known that different organisations use Cloud Foundry in production on AWS, vSphere, OpenStack, Google Compute Engine among others. Azure has been also added to this list.
Also, as mentioned, we would not switch IaaS to troubleshoot an issue like this one without first understanding its root cause.
Please refer to the great post from Anna Shipman, "Choosing Cloud Foundry for the Government Platform as a Service" (https://governmentasaplatform.blog.gov.uk/2015/12/17/choosing-cloudfoundry) to know more about why we have chosen this stack after comparing different alternatives (https://gdstechnology.blog.gov.uk/2015/10/27/looking-at-open-source-paas-technologies).
And remember that we code in the open (https://gds.blog.gov.uk/2012/10/12/coding-in-the-open). Do not hesitate to check out our early alpha setup. This one was built to be deployed on multiple providers https://github.com/gds-attic/paas-alpha-cf-terraform (AWS,Google Compute Engine and Azure).
Comment by Juan Pablo Genovese posted on
Fantastic article. Thanks for the detailed explanation. I think that reverse engineering is one of the hardest, yet rewarding, experiences for any developer/DevOps engineer.