On April 17th, deep in the pre-election period, we released a new search feature that allows GOV.UK users to search inside long-form web documents called Manuals. If you want to have a look at this feature, head over to gov.uk/guidance/content-design and get searching.
During development, we discovered very inefficient code in the Mustache gem which caused us major unexpected problems. This blog post covers that problem and how we fixed it.
The problem
The search pages on GOV.UK use Mustache for templating. This allows them auto-update results using JavaScript if the user amends their search terms. As part of introducing the new feature, I refactored some Mustache into a partial.
You can take a look at the original pull request here. A simplified version is below:
<!--Before-->
<ol>
{{#results}}
<li>
{{result.title}}
[...]
</li>
{{/results}}
</ol>
<!--After-->
<ol>
{{#results}}
{{>search/_result}}
{{/results}}
</ol>
For those not familiar with Mustache, this says "iterate through the `results` array and pass each `result` into the `search/result` template". This is not an unusual or un-Mustachey thing to be doing. Indeed, something very similar is shown in the Mustache documentation to explain partials.
This code got merged into master which was then automatically deployed to our preview environment (a production-like environment where we test new features). It seemed fine. A few days later we came to deploy it to production. That’s when we noticed something was not quite right.
When deploying, before something goes live on GOV.UK, we deploy it to our staging environment. Staging is set up to be exactly like our live site. We re-play all traffic from live against staging.
We tested the change on staging. Everything looked right so we moved on to deploying to production. Shortly after deploying to production, we noticed a spike in 504 timeout errors. Timeouts aren't unusual during a deployment, and our stack absorbs most of them without any user impact. But this number was unusually large. It also appeared to be climbing on both staging and production. We decided to roll back production and investigate on staging.
We saw a big spike when looking at our CPU usage graphs for staging. The code we had just deployed was causing much higher CPU usage than usual. This in turn increased our response times. In some cases this was causing the requests to time-out.
You can see the staging graph below.
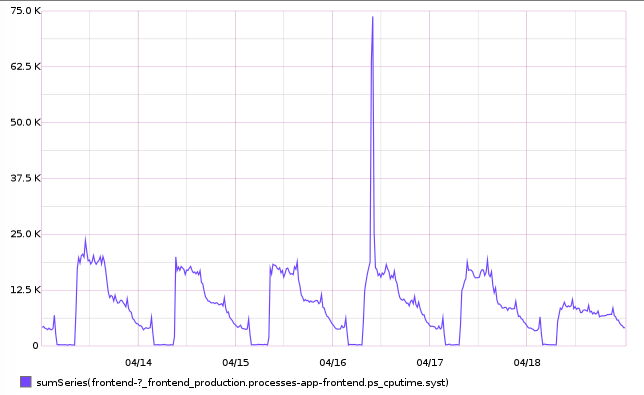
We went back to our preview environment, where this code had been deployed for a few days. We took a look at the CPU usage graph, which you can see below. Sure enough, it shows that just after this code change was merged, there is a large increase in CPU usage. The reason this hadn't caused an increase in HTTP 504 errors is because the traffic to preview is much lower than that on staging and production.
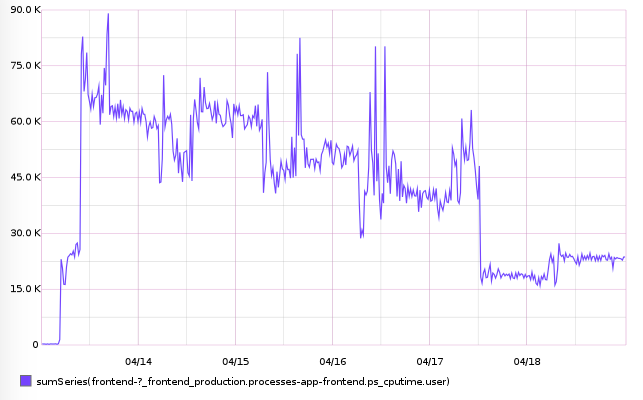
Exciting! It's not often, as a front-end developer, that you can do something that makes the server this unhappy.
Debugging
Luckily this was a pretty small set of changes (deploy often, kids!) so it was reasonably easy to track this down to some likely culprits. We used ruby-prof, a code profiler for Ruby, to profile the old code running next to the new code and saw a massive increase in the number of calls to CPU-intensive string functions coming from Mustache. Below is the profile from the search controller before and after the code was refactored into a partial.
The original dumps can be found in this gist on Github.
| calls |
name | old | broken |
<Class::Regexp>#escape | 399 | 2445 |
Mustache::Generator#ev | 75 | 454 |
Mustache::Generator#on_fetch | 74 | 450 |
Mustache::Generator#str | 104 | 623 |
Mustache::Parser#compile | 2 | 13 |
Mustache::Parser#otag | 254 | 1559 |
Mustache::Parser#position | 109 | 663 |
Mustache::Parser#regexp | 179 | 1095 |
Mustache::Parser#scan_tags | 110 | 675 |
Mustache::Parser#scan_text | 110 | 675 |
Mustache::Parser#scan_until_exclusive | 110 | 675 |
String#== | 412 | 2249 |
String#=== | 351 | 2085 |
String#[] | 436 | 2277 |
String#split | 232 | 1399 |
StringScanner#pos | 539 | 3198 |
StringScanner#scan | 437 | 2664 |
StringScanner#scan_until | 110 | 675 |
StringScanner#skip | 341 | 2110 |
It turns out that Mustache doesn't do any caching for partials. That means that even though the content is static, each time the partial is used the following steps are taken:
- read the partial from a file into a string
- indent that string to the right level
- turn indented string into a template
For large partials, compiling the template is computationally expensive. On search results pages, we were paginating at 60 results, so instead of doing this work once we were doing it 60 times in the worst case.
Short term fix
Short term, the fix to allow this change to be deployed was to squash the `result` template back into its parent, and use recursion to avoid having to duplicate the template code for nested results.
This change gets the number of calls to those CPU intensive string functions back down to a sensible level. You can see the call counts for before, during and after this work below:
name | calls |
| old | broken | fixed |
<Class::Regexp>#escape | 399 | 2445 | 693 |
Mustache::Generator#ev | 75 | 454 | 130 |
Mustache::Generator#on_fetch | 74 | 450 | 126 |
Mustache::Generator#str | 104 | 623 | 171 |
Mustache::Parser#compile | 2 | 13 | 4 |
Mustache::Parser#otag | 254 | 1559 | 439 |
Mustache::Parser#position | 109 | 663 | 189 |
Mustache::Parser#regexp | 179 | 1095 | 313 |
Mustache::Parser#scan_tags | 110 | 675 | 190 |
Mustache::Parser#scan_text | 110 | 675 | 190 |
Mustache::Parser#scan_until_exclusive | 110 | 675 | 190 |
String#== | 412 | 2249 | 734 |
String#=== | 351 | 2085 | 591 |
String#[] | 436 | 2277 | 725 |
String#split | 232 | 1399 | 451 |
StringScanner#pos | 539 | 3198 | 935 |
StringScanner#scan | 437 | 2664 | 757 |
StringScanner#scan_until | 110 | 675 | 190 |
StringScanner#skip | 341 | 2110 | 602 |
This fix works fine but the code is not particularly readable. Frontend is a highly collaborative repository. Many developers might stumble into it and need to make changes, so making sure the code is easy to understand is a priority.
Long term fix
Using partials in this way is a common use-case so it's pretty likely that someone else is going to have the same problem we did. A better solution would be to fix this problem in the Mustache gem if possible.
The Mustache gem already has caching for templates, but not for partials. We decided the best solution was to introduce partials caching. A previous pull request to introduce partials caching was rejected because it would have caused a memory leak for users who dynamically generate partials as they would never get garbage collected.
We opened a new pull request against the Mustache gem, which introduces caching at a very low level and doesn't include a memory leak issue for anyone using dynamic partials.
The caching we added shows a ~16-20x speed increase in rendering repeated partials, depending on how it’s used. For complex partials the rendering can be more than 50 times faster. Now, everyone using the Mustache gem will benefit from this speed increase, not just GOV.UK.
Credits
Thanks to @jenny_duckett and @rjw1 for the devOps help and @evilstreak and Mike for the help with Mustache wrangling.
