GOV.UK has used a Content Delivery Network (CDN) since its transition from beta to live in October 2012. When the contract with our first CDN provider came to an end in September 2013, we took advantage of what we'd learned and some improvements in our purchasing options to shop around and save some money.
The new CDN needed to behave exactly like the old did. This was difficult because:
- we had no detailed technical specification of everything that we wanted (and didn't want)
- configuration formats are specific to each provider and are often intertwined with their own defaults
- we had some non-standard requirements like failover to additional origins (as described in Kush's blog post about disaster recovery)
To help us with the migration, we scripted some A/B tests of URLs sampled from normal traffic and performed manual verifications using curl. We also received help from both our new and old providers, to their absolute credit. The migration was a success and we went away with a better idea of what we might do differently in the future.
Earlier this year we started looking at running GOV.UK behind a second CDN in parallel with our existing one, with the aim of improving our technical resiliency and reducing our business dependency on any one provider. In order to do this, we'd have to be more certain than ever that both CDNs implemented the same features and behaviours. Otherwise users might experience non-deterministic bugs which would be very hard for us to monitor or debug.
Test concept
The popularity of Infrastructure as Code has meant that the infrastructure of today should have the same qualities of any good software project, such as version control and testing. The CDN is an extension of our normal infrastructure, so why not treat it the same way?
We were already some way towards this by version-controlling our CDN configurations and using one-click deployments. What we were missing was automated testing to confirm that our new features worked and that we hadn't broken any existing features in the meantime. We searched and asked around for existing solutions but couldn't find any.
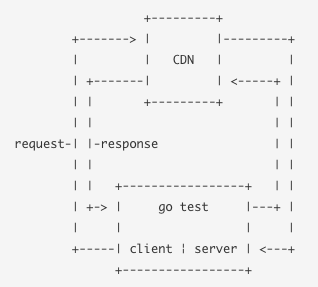
I figured that to test a CDN, which could be thought of as a black box with an input and output, it would look something like this:
- create an HTTP request against a CDN
- observe the request forwarded from the CDN to a server in our control
- create an HTTP response based on some conditions
- observe the response returned from the CDN to our client
This all needed to be wrapped in a simple test runner that would repeat the process many times and report on the observations (assertions about incorrect results). Based on some experience working on the GOV.UK router and gor I thought that this would be quite straightforward to implement in Go with the standard library packages net/http and testing.
I started out by writing some empty/failing tests that described many of the behaviours we expected from a CDN and an ASCII diagram that visualised the steps described above. I was then joined by Mike Pountney, who hadn't used Go before, but you wouldn't have known it after a few days in.
Implementation details
Here is a tour of some notable features and solutions that we encountered while writing the test suite. Throughout I'm going to use the term "edge" to describe servers that belong to the CDN and "origin" to describe servers that belong to us.
Configuration deployment
Because we already had a mechanism for version-controlling and deploying our CDN configurations, it was decided that this new project shouldn't be responsible for managing configurations at all.
This turned out to be a very good thing because:
- it allowed us to be much more provider agnostic and the work required to initially test a new provider was greatly reduced
- it meant that we could test an identical configuration, except for hostnames, in production and staging
Mocking a CDN
Two people developing and running tests from the same server against the same CDN service quickly proved to be a bottleneck. We needed a way to independently run the test suite offline.
One of our CDN providers have built their service upon an open source HTTP caching server called Varnish. Since a CDN is mostly just an external distributed HTTP cache, Varnish already does most of the things that we want to test, and we're familiar with using it in the GOV.UK stack. It doesn't support TLS in either direction but Nginx and stunnel can handle that. We created a Vagrant virtual machine which uses a set of Puppet modules to configure all of these components into something that behaves like a CDN. There's another ASCII diagram to show how it fits together:
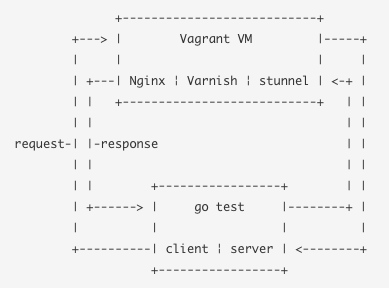
An unforeseen benefit of having this was that we could re-use the same mechanism to run continuous integration tests against pull requests for all newly created and amended tests in our suite. This gave us much greater confidence when reviewing each others' changes.
Backend request and response handling
Each of our tests needed to make the origin server behave in a different way, sometimes more than once per test, such as:
- making assertions about the contents of the request received from the CDN
- responding with particular status codes, headers, and bodies
- asserting when we shouldn't receive a request at all eg. when cached
We created a CDNBackendServer struct which represents a single backend bound to a local port. Multiple instances can be bound to separate ports. These run concurrently to the tests in the foreground using goroutines and satisfy the interface for http.Handler by implementing CDNBackendServer.ServeHTTP(), which gets called for every request.
Requests for HEAD /, which are used by some CDN providers as health checks to determine whether origin is up, are always served a 200 response. All other requests get passed through to a handler function which each test can replace by passing a function literal (an anonymous and not yet invoked function) to CDNBackendServer.SwitchHandler().
In some places we also take advantage of the following from the Go spec about function literals:
Function literals are closures: they may refer to variables defined in a surrounding function. Those variables are then shared between the surrounding function and the function literal, and they survive as long as they are accessible.
We combine this with the fact that an HTTP client request is a synchronous operation that won't return, if successful, until our handler has been executed. This means that we can declare variables at the beginning of the test and then assign values when we receive a request, such as recording the values of request headers or incrementing a count of requests received.
Stoppable backends
To test the CDN's handling of errors and failover we needed the ability to stop the backend (unbind from its assigned port) to prevent it accepting connections for requests.
This isn't possible with the simplest and most common method of starting an HTTP server in Go becausehttp.ListenAndServe doesn't expose anything for you to stop. Thankfully, while the Go standard library provides convenience functions like this, it also has all of the component parts for you to build your own thing - like a set of building blocks. Furthermore, the source code for the standard library is incredibly readable and well linked from the online documentation, which allows you to see how parts are composited.
We started by reproducing http.ListenAndServe, which underneath creates an http.Server and calls http.Server.ListenAndServe(), which underneath that creates a net.Listener (that we want to close) and passes it to http.Server.Serve(). However closing the listener didn't have the desired effect because existing connections, particularly those using HTTP keepalive, remained active.
While searching for a way to close outstanding connections we came across some code that did what we want - lo and behold from Go's standard library. httptest.Server is a handy wrapper which keeps track of client connections and provides an httptest.Server.Close() method which waits until all outstanding connections have been closed. To make use of this we needed to bring our own listener and wrap the Close() method.
TLS backends
Initially our tests used plain-HTTP backends with no Transport Layer Security (TLS) because we didn't want the complexity of certificates to get in the way of validating the concept. However, all of our real interactions with CDNs only use HTTPS (HTTP + TLS) backends, so our tests eventually also needed to do the same.
httptest.Server helped us here also. It comes with its own self-signed certificates and ability to swap our Start() call with StartTLS(). Later on we made TLS mandatory and allowed the certificates to be overridden from the command line.
Backend health checking
We found that our tests often failed for CDN providers that use periodic health checks; sometimes consistently at the beginning of the test suite and sometimes intermittently throughout the run. This was because the backends hadn't responded to enough health check requests for them to be considered healthy.
There's no way to query the health check information directly from the edge. Even if there was, it's unlikely that we'd get the same information from all providers. Instead, we found a solution that relied on the fact that the edge would only forward a client request to a backend that it considers healthy. waitForBackend makes requests against the edge and checks that the backend returns the correct identifier. When we've received a certain amount of the correct responses then we know that it's safe to proceed.
This was complicated slightly when we introduced multiple backends that are used by the edge in priority order. If the first backend was up then it would receive all of the requests and we'd have no way of knowing whether the second and third backends were healthy. ResetBackends solved this by starting the backends in reverse-priority order. It's called at the start of the test suite and then again before test. If any stopped backends are encountered then it will stop all backends of a lower priority and start them back up again from the bottom.
DNS caching
Some of our early tests suffered from intermittent failures; in particular those which made more than one request, such as populating the cache and checking that the item was still there.
Most CDN providers use a Global Server Load Balancer (GSLB) solution which uses DNS to route end users to the nearest edge servers. The DNS responses have a low time-to-live (TTL) period because decisions about the nearest, fastest, or currently available location, can frequently change.
To prevent us changing locations in the middle of a test, we had to cache the DNS lookup ourselves. In another example of how working in Go is like constructing with building blocks, it allows us to pass our own net.Dial function literal (responsible for making network connections) to http.Transport (responsible for HTTP transactions). Our CachedHostLookup short circuits the DNS lookup and then hands over to the stock net.Dial function.
Request helpers
There were some patterns that we repeated while writing the tests and which made sense to consolidate into helper functions that could be shared. For example:
NewUniqueEdgeURLwhich generates new URLs using the edge's hostname and a query parameter containing a random UUID to ensure that every test starts with an uncached resourceRoundTripCheckErrorwhich executes a request and performs error checking - registering a test error if it takes longer than a threshold period of time to complete and aborting the calling test if there are any errors in the transactiontestThreeRequestsNotCachedwhich repeats a request and checks for unique responses, optionally modifying the response headers at the same time - this vastly reduced the amount of code inTestNoCache*
In a shining example of premature optimisation, I attempted to write some of these helpers too early and failed. I was unable to identify the right patterns to de-duplicate and hampered some of the good patterns that we went on to develop in individual tests. We were only successful in writing the helpers at a later stage when we had a better idea of all the use cases.
Bugs uncovered
Unsurprisingly, when you begin to test something for the first time, you uncover a lot of bugs that you never knew existed. Some of which your providers never knew existed either (we're sorry!).
If you have to spend any time investigating what a correct implementation of HTTP/1.1 is then it's worth going straight to RFC 723X. It's the recently published revision of RFC 2616 from 1999, which is now a lot more readable and detailed, but isn't always the first result you'll get from a search engine.
Case sensitivity
Deep in the mists of time, for reasons that we don't remember, we enabled an option with our first CDN provider that treated cached request paths as case-insensitive. Our origin has always been case-sensitive, which is the correct behaviour for the web, so this mismatch led to some intermittent and surprising results.
There are a limited number of top-level redirects on GOV.UK for organisation acronyms such as https://www.gov.uk/mod. At the time, case variations such as /MoD weren't redirected by origin, but they worked most of the time because they would be satisfied by the cached object for /mod. Except when the cached object expired and coincided with a request for /MoD, which origin didn't know about, a 404 would be cached and also served for the "correct" requests of /mod. This didn't happen very often which made it very hard to debug and fix.
In response to bug reports from users and analytics we solved this early last year by explicitly handling common case variations for acronyms such as /mod, /MoD and /MOD, and then turned off the case-insensitive option so that edge behaved the same as origin.
To prevent it happening again, with new or existing providers, we wrote a test called TestCacheUniqueCaseSensitive which ensures that case variations of the same word are cached independently.
Protocol redirects
GOV.UK content is only ever served over HTTPS. For convenience we redirect users from http://www.gov.uk tohttps://www.gov.uk and this has always been performed by our CDN without the need to hit origin. Though in practice it is superseded by Strict Transport Security for return visitors.
A long time ago we received some support requests because this redirect wasn't preserving query parameters. For examplehttp://www.gov.uk/search?fish was being redirected to https://www.gov.uk/search without the original search terms. This was caused by a mistake in our CDN configuration. We fixed it, but there was also the chance that we could break it again when moving to another provider.
By writing TestMiscProtocolRedirect we know that this won't happen again. It also gave us cause to investigate whether URL fragment identifiers should be preserved in the redirect - the answer according to RFC 7231 is that the Location doesn't need to contain the fragment and that the client should re-apply it if omitted.
Denying PURGE requests
We'd previously discovered that anyone could invalidate cached content from our edge and force a new response from origin by issuing a PURGE request to edge. We didn't want to allow this, so we spoke to the affected CDN provider and they recommended a fix, which returned a 403 response if the request didn't come from a whitelisted IP address. The implementation had a quirk in that that we had to modify the internal representation of the request method from PURGE to GET in order to deliver the correct response to the client. It tested out fine, we deployed, and got on with other work.
The amount of custom code in our configuration to implement this change made it a good candidate for the new test suite. We wrote a test to mimic the manual testing from before; make a request from a non-whitelisted IP and assert that we got a 403 response. We now also had the ability to assert that the request shouldn't make it to origin. It failed:
=== RUN TestMiscRestrictPurgeRequests
--- FAIL: TestMiscRestrictPurgeRequests (0.12 seconds)
cdn_misc_test.go:58: Request should not have made it to origin
cdn_misc_test.go:75: Request 2 received incorrect status code. Expected 403, got 200
So the behaviour had changed since we fixed it and we hadn't noticed. It turned out that modifying the request method was no longer necessary, and by doing so the edge now treated it as a normal GET request to origin. It wasn't the provider's fault - it was our config and they can't support everyones customisations.
We fixed it and verified with the tests. We also improved the test by populating the cache and checking that the object hasn't been invalidated, which is the behaviour that we really care about rather than the response code. You can see the complete test as TestMiscRestrictPurgeRequests.
Expires headers
The Expires header is one way to specify the TTL of a response by the date and time at which it will expire. It can be dependent on accurate machine clocks and it will be ignored if specified alongside Cache-Control, but otherwise it's still a valid directive.
TestCacheExpires found that one provider didn't support this at all. The directive was ignored and a default TTL applied with a new Cache-Control header.
=== RUN TestCacheExpires
--- FAIL: TestCacheExpires (6.85 seconds)
helpers.go:368: Request 3 received incorrect response body. Expected "subsequent response", got "first response"
helpers.go:377: Origin received the wrong number of requests. Expected 2, got 1
Prevent caching with Cache-control
The Cache-Control header has a number of directives to specify how a request or response should be cached. In addition to TestCacheCacheControlMaxAge testing that cache TTLs were respected we also tested that the edge would respect our decision not to cache by using private, no-store, no-cache, and max-age=0 in TestNoCacheHeaderCacheControl*.
The results were surprisingly inconsistent across the board. With a few configuration changes we made most of them work as expected. But it's clear to see why you often see them all specified together.
X-Forwarded-For
The X-Forwarded-For request header, while not part of the official specification, is commonly used to convey the IP address of the original client and any intermediary proxies. It shouldn't necessarily be used for verification purposes but it can be good for informational use. There were two minor problems surfaced by TestReqHeaderXFFCreateAndAppend.The first, with one provider, was that we were seeing the same value repeated. This was caused by a copy/paste mistake in our CDN configuration that we'd never noticed.
=== RUN TestHeaderXFFCreateAndAppend
--- FAIL: TestHeaderXFFCreateAndAppend (0.00 seconds)
cdn_acceptance_test.go:86: Expected origin to receive "X-Forwarded-For" header with single IP. Got "80.240.128.97, 80.240.128.97"
The second, with another provider, was a whitespace difference in the string that we were matching against. There are some clues about what we should allow in RFC 7239 which defines a new single purposeForwarded header and the list extension in RFC 7230 specifies that list items are separated by a comma and optional whitespace. The fix was to replace our string comparison with checks for the individual list items.
=== RUN TestReqHeaderXFFCreateAndAppend
--- FAIL: TestReqHeaderXFFCreateAndAppend (0.03 seconds)
cdn_req_headers_test.go:56: Origin received "X-Forwarded-For" header with wrong value. Expected "203.0.113.99, 80.240.128.97", got "203.0.113.99,80.240.128.97"Vary and Accept-Encoding
The Vary response header is used to specify that a cached response should only be used to satisfy another request if all of the nominated headers match the original request. One very common use of this is Vary: Accept-Encoding which can prevent gzip compressed responses from being delivered to clients that haven't requested it with Accept-Encoding: gzip. There are also many other powerful ways to use Vary.
TestCacheVary found that not all providers supported this. Based on this inconsistency we added TestCacheAcceptEncodingGzip to verify that gzip compression worked as expected, which we found it did but didn't always seem to depend on Vary in responses.
The specification also says that responses with Vary: * should never be cached but TestNoCacheHeaderVaryAsterisk found that this was rarely implemented and we've had to disable the test for now.
Authorization, Cookie and Set-Cookie
HTTP caching often raises concerns about privacy. You don't want a response that has been personalised with account details for one user to be delivered to another user. Most well behaved applications should emit the appropriate Cache-Control headers to reflect this.
The Authorization request header is used to provide authentication credentials. Blindly caching a successful response would allow other clients to bypass authentication and for that reason RFC7234 states that such responses must explicitly opt-in to be cached. In reality TestCacheHeaderAuthorization found that most CDN providers will cache these with a default TTL, although when asked they weren't sure why their configurations had evolved in this way.
=== RUN TestCacheHeaderAuthorization
--- FAIL: TestCacheHeaderAuthorization (0.11 seconds)
helpers.go:378: Request 2 received incorrect response body. Expected "first response", got "subsequent response"
helpers.go:378: Request 3 received incorrect response body. Expected "first response", got "subsequent response"
helpers.go:387: Origin received the wrong number of requests. Expected 1, got 3
The Set-Cookie response header is used to provide cookies to a client. Cookies can contain data that uniquely identifies a user, such as a login session or server-side analytics, which you wouldn't want to be cached. However not all cookies are sensitive, so RFC7234 states that Set-Cookie responses can be cached and should explicitly opt-out where necessary. TestCacheHeaderSetCookie identified that we needed to change our configuration with one provider.
=== RUN TestCacheHeaderSetCookie
--- FAIL: TestCacheHeaderSetCookie (0.11 seconds)
helpers.go:374: Request 2 received incorrect response body. Expected "first response", got "subsequent response"
helpers.go:374: Request 3 received incorrect response body. Expected "first response", got "subsequent response"
helpers.go:383: Origin received the wrong number of requests. Expected 1, got 3
The Cookie request header is used by the client to provide previously set cookies to the server. It's worth noting that your server-side application may not be responsible for setting and reading cookies if it's all done in client-side scripting, but they'll be provided in a request header regardless. If you weren't to cache these then you wouldn't benefit much from using a CDN. TestCacheHeaderCookie confirmed that this worked on both providers.
In all three cases we had to change the default behaviour of Varnish in the mocks to match that of the CDN providers. I can only attribute this to there being different requirements for localised caching (at and within origin) compared to edge caching, such as the need to improve hit/miss ratios because the round-trip time is much greater.
Age
The Age header indicates how long has elapsed since the origin generated (or revalidated) a response. This can be useful for debugging how long a cache has held onto a response and when it may expire in relation to the Cache-Control directive. RFC 7234 describes the mechanism for calculating this value, which should respect an initial value provided by origin and then increment it.
TestRespHeaderAge found that one provider didn't support this. No header was added to responses that didn't already have one and was unmodified (not incremented) for responses that did. This is now on their roadmap to be implemented.
=== RUN TestRespHeaderAge
--- FAIL: TestRespHeaderAge (5.13 seconds)
cdn_resp_headers_test.go:68: Age header from Edge is not as expected. Got "100", expected '105'
Serve stale
As part of our disaster recovery solution that falls back to static mirrors at other locations we also attempt to serve a stale response (beyond its normal TTL) from cache if one is available. Historically our static mirrors have only been updated once every 24 hours and don't contain dynamic content such as search, so there's a much greater chance that the stale response is more appropriate than the static mirror.
This has been implemented with each provider at varying levels of difficultly ranging from it being the default behaviour to implementing it ourselves. In the past we have written some varnishtest tests to prove the concept, but have had a great deal of trouble testing it in the real world where all of the testing had to be orchestrated manually by stopping, starting, and reconfiguring web servers to return the appropriate responses.
With TestFailover* we were able to for the first time verify whether the real thing worked and in a provider agnostic way. The result? It wasn't working quite as we'd hoped, but it wasn't a complete surprise to us. It confirmed that we were dependent on health check expiry and that requests were retried against origin too frequently. We're still in the process of improving the implementation and the tests will now serve as our acceptance criteria when we're done.
Conclusion
Identifying and documenting the existing behaviours proved to be incredibly valuable. Some of the bugs lay previously undiscovered because our manual tests weren't reliable or thorough enough. While other bugs were surfaced for the first time because we were now thinking about scenarios that either we hadn't previously, or had in the past but since forgotten about.
We now have a much better specification of what we want. As regularly executed code, which produces a boolean pass/fail result, it's less likely to fall out-of-date as is often the case with written documentation. We can use the tests to prevent regressions with our existing providers and as a reference when talking about requirements with new providers.
In fact, something which proved to be a major advantage, was the ability to point our providers' technical employees directly at the source code. The tests were more succinct than explaining step-by-step commands and expected output as we have done previously. They could also re-run the tests themselves to reproduce the issue and verify that their fixes worked.
The code for the complete project is open source under the MIT license and available on GitHub:
If work like this sounds good for you, take a look at Working for GDS - we're usually in search of talented people to come and join the team.
You can follow Dan on twitter, sign up now for email updates from this blog or subscribe to the feed.

3 comments
Comment by Александар Симић posted on
Interesting post, thanks for taking the time to write it up.
ASCII diagrams, nice choice, although they don't render so well on certain fruity company's browser.
Comment by Dan Carley posted on
Thanks. I've just replaced the diagrams with images, which shouldn't suffer from the same problem.
Comment by Samuel Isales posted on
Great, helpfull gov website!
https://www.peterborough.gov.uk/download/75383/