We recently completed an alpha on identity assurance for organisations. The objective of an alpha is to gain understanding of a service and validate a design approach by building a working prototype. As part of the alpha, we built a set of interacting prototype applications representing a number of separate services as assurers and consumers of identity information. Because our objective was understanding and validation, these prototypes did not use any real user’s data.
We wanted our prototype to:
- evolve rapidly, adapt quickly to feedback from our user research, and to be able to change direction entirely if necessary
- be realistic enough to validate whether the service we were exploring was technically feasible
- be simple and focus on the service we were trying to explore, rather than getting bogged down in implementation details
However, we didn’t need to worry about maintaining the code long-term: because the objective was better understanding through building a prototype, we were prepared to throw the code away at the end.
The focus of the alpha was to find a way for users to use the same system across multiple government services, therefore we knew we’d want to model multiple independent services. We built a prototype service to represent an example government service, and another service to represent an authentication server. Here is a simplified view of the kind of authentication flow we were exploring:
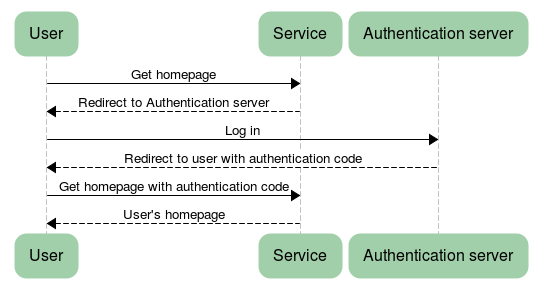
We chose to implement our prototype in Clojure, a JVM-based language. As a language with a focus on REPL-based development, we felt that it had potential to give us fast feedback; and we felt Clojure had good support for JSON which would enable us to investigate OpenID Connect effectively. In parallel with the development effort, we also had a static site prototype for performing user research.
Two members of our team had some previous experience with Clojure (I have just returned from speaking at EuroClojure 2014) while two were completely new to it.
Time to pick up the language
Although it was a relatively short project, we were quickly able to pick up enough familiarity with the language to be effective. Leiningen was easy to install and handled all the other dependencies, so setting up a dev environment was painless. We all used emacs with cider, a module for emacs which connects to a running Clojure application and allows dynamically redefining parts of it.
Along with emacs/cider, we used Stuart Sierra’s reloaded flow, which determines which source files have changed and therefore which namespaces need to be reloaded in the running development environment. It took some effort to get it working, but once it did work it dramatically improved our development experience. Seeing the effect of a code change, small or large, was a simple matter of calling (reset) from the REPL.
Rapid prototyping
Clojure enabled us to move quickly, both in the UI and in the backend. Our prototyping in the backend was mainly about investigating JSON-based data flows. Clojure is very well suited to passing maps and lists around, and so it’s no surprise that it plays well with JSON. The other main language in the GDS identity assurance ecosystem is Java, where JSON processing often involves a lot of boilerplate code to define JSON structure. An example from the tutorial for Jackson, a Java JSON library, reads the following data:
{
"name" : { "first" : "Joe", "last" : "Sixpack" },
"gender" : "MALE",
"verified" : false,
"userImage" : "Rm9vYmFyIQ=="
}
Although the code for reading and writing JSON is short, it depends on User and Name classes being defined to give structure to the data: to indicate which fields exist and what their expected types are:
public class User {
public enum Gender { MALE, FEMALE };
public static class Name {
private String _first, _last;
public String getFirst() { return _first; }
public String getLast() { return _last; }
public void setFirst(String s) { _first = s; }
public void setLast(String s) { _last = s; }
}
private Gender _gender;
private Name _name;
private boolean _isVerified;
private byte[] _userImage;
public Name getName() { return _name; }
public boolean isVerified() { return _isVerified; }
public Gender getGender() { return _gender; }
public byte[] getUserImage() { return _userImage; }
public void setName(Name n) { _name = n; }
public void setVerified(boolean b) { _isVerified = b; }
public void setGender(Gender g) { _gender = g; }
public void setUserImage(byte[] b) { _userImage = b; }
}
If the JSON structure ever changes, say by adding or renaming a field, those classes will need to be updated. Furthermore, since JSON is commonly used to communicate between separate processes, both ends of a communication channel will need a User class, and both will need to update their classes if the JSON payload changes.
Compare this to our experience in Clojure, where the data can be read without any supporting code:
(clojure.data.json/read-str json-str :key-fn keyword) which produces:
{:name {:first "Joe", :last "Sixpack"}, :gender "MALE", :verified false, :userImage "Rm9vYmFyIQ=="} Being able to just add fields to a JSON map without having to change a schema was a powerful way to experiment with the API. Clojure’s built-in syntax and library support for rich data structures, and its dynamic nature, meant evolving a JSON API was a very low-friction activity.
On the frontend side, we used enlive for templating. Enlive uses raw HTML documents as templates, and allows you to replace subtrees of the document using CSS selectors. This means that you can open the template itself in a browser and see what it will look like, with example content in the sections to be templated, making it designer-friendly. We considered the idea that the templates we were developing could be directly used for user research, since they are complete, valid, HTML documents. However in practice the static prototype tested with users evolved much more quickly and experimentally than the application we were building, so they remained separate.
Unfortunately enlive doesn’t have mature auto-reload support, so HTML files that had changed on disk wouldn’t be picked up by the running application. We ended up manually triggering a reload of our enlive-consuming namespaces via the REPL in order to pick up UI changes. This compares unfavourably to environments such as Rails or PHP where changes to templates are made immediately visible in the running application.
Heroku
We were able to deploy our prototype apps to heroku. Heroku worked really well for our use case: we were able to deploy multiple independent apps, connect Postgres databases, and we didn’t have to worry about setting up individual servers.
Testing
We didn’t do a lot of testing on this project: after all, the goal was to gain context and understanding of the business problem, not to write production-quality code. So our tests were limited to those that we thought could make us go faster or help us understand the problem within the 12-week project timescale.
We used kerodon for user journey testing, since one outcome we wanted was a solid understanding of the user journeys in this system. Kerodon is a tool based on Ruby’s capybara which allows fast in-process user journey testing; it does this by calling a Ring handler directly. Most of our interesting flows started at the prototype service, were redirected to the authentication server, and then redirected back to the service, via an OpenID Connect authentication flow; we wanted to test these flows that touched multiple separate web services.
It’s easy to take multiple Ring handlers for separate services and compose them together using a higher-level handler which dispatches to a service based on the HTTP Host: header. This meant that we could present our multiple independent services to kerodon as a single Ring handler, and it could interact with each of the services just by following redirects. This allowed us to run the full environment in memory, with each service able to redirect to each other, so our user journey tests ran very quickly.
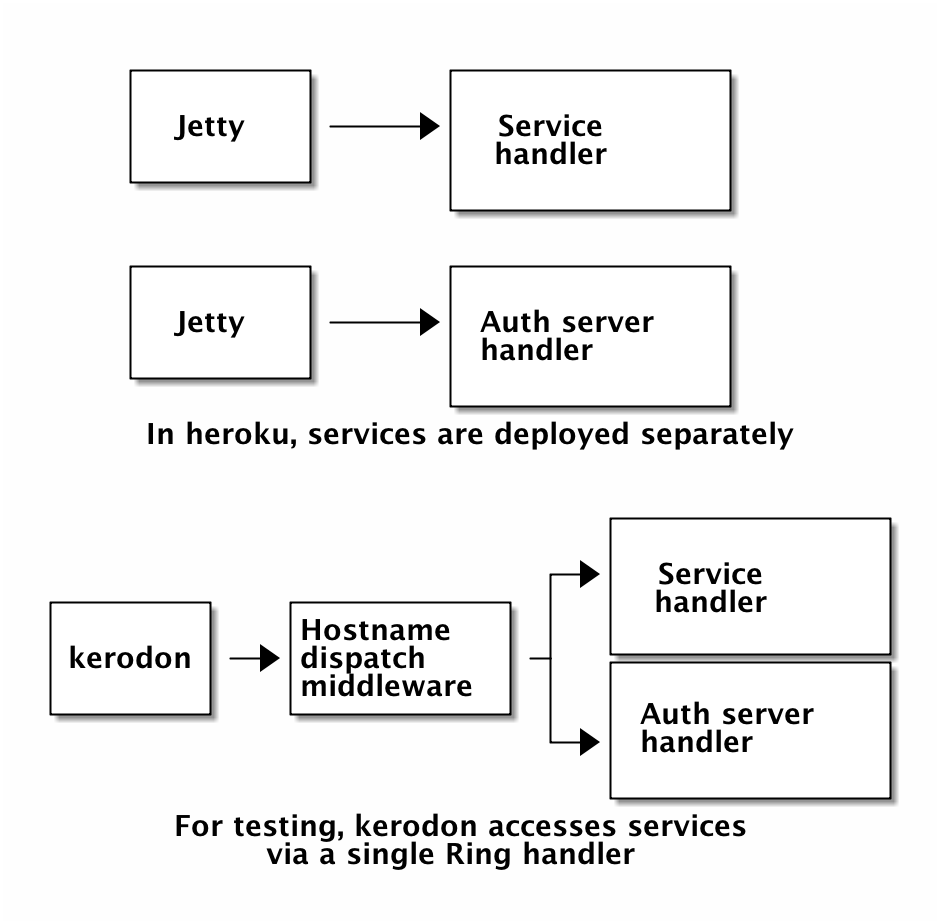
Kerodon also made it easy to test journeys involving two or more users: you just create separate kerodon sessions and they will have independent cookie jars with separate session cookies.
We didn’t write many low-level tests, just one or two midje and test.check tests; but Clojure’s emphasis on small functions, with no side-effects where possible, meant that we could go back and add tests without restructuring the code too much if we needed to.
Documentation
Although the core documentation was reasonable, the community documentation for the various libraries we used varied wildly. It wasn’t always easy to understand how to use a new library we were trying to adopt. There are no surprises here; lack of documentation has been a consistent message in the State of Clojure survey.
Security
We watched Aaron Bedra’s Clojure/West 2014 talk clojure.web/with-security with interest. Naturally, security is very important in applications which deal with identity, and so we were concerned with the issues that Aaron raised: that Clojure’s libraries-not-frameworks approach means that rather than being secure by default, you have to deliberately choose and include libraries to protect against particular attacks. We echo Aaron’s call for improvement in the Clojure ecosystem to make building secure webapps much easier. This wasn’t a problem for a prototype, but would certainly factor into a decision as to whether to use Clojure for a real service.
Stubbing
We used static functions to access the database. In tests, where we wanted to test code without interacting with the database, we ended up needing to use a lot of with-redefs to temporarily replace our repository functions with stubbed versions. This was problematic in a number of ways: we didn’t stub consistently the same way each time, and we didn’t create a stub implementation which would actually maintain data in memory, and instead largely just stubbed database operations out as noops. This meant we often weren’t testing interactions that we thought we were testing, and instead just hard-coding the repository to return values we expected to see. On a longer-lived project, we would definitely want to explore alternatives to with-redefs for subtituting stub implementations, such as Component, or one of Joseph Wilk’s suggestions.
Error reporting
Stack traces are not terribly meaningful. Some of the recent cider updates have gone some way to help hide irrelevant stack frames, but often it’s hard to understand what exactly has gone wrong. Some situations, such as returning invalid data from a Ring handler causing an exception in a middleware, result in stack traces which don’t contain any user code at all, making it very difficult to trace the cause of the error.
Overall
Would we use Clojure again for a prototype? If we had the same people on the team, then yes. We have enjoyed working with this language, and we have been productive in it. It satisfied to every requirement we had for this prototype. However we recognise that if the team hadn’t had in-house Clojure expertise from the start, the story may have been different.
We don’t have the experience to talk about using Clojure for larger systems. In particular, we don’t know how programming in the large works for Clojure: how to refactor existing Clojure codebases, how to structure namespaces, how to split a monolithic set of compojure routes into multiple constituent pieces. These caveats aside, Clojure is definitely a language we would consider exploring further.
If work like this appeals to you, take a look at Working for GDS - we're usually in search of talented people to come and join the team.
You can follow Phil on Twitter, sign up now for email updates from this blog or subscribe to the feed.

2 comments
Comment by Alex Miller posted on
Regarding Aaron's security talk - that talk spurred immediate action from a number of parties. I would not say that the work is done, but many of the suggested changes have already been integrated or created since the talk. It's due for an update!
Splitting compojure routes into pieces is fairly straightforward by using compojure.core/routes instead of defroutes.
Comment by Philip Potter posted on
Thanks for the clarifications. It's great to hear there's a lot of activity; I've certainly noticed quite a bit of talk on the clojure mailing list and in Malcolm Sparks' EuroClojure talk. As you say, though, the work is not yet done: in particular, I'm still not sure there's an easy way to generate a secure-by-default webapp in the way that frameworks like Rails allow. I'd be very pleased to be proven wrong, though!